Preserving Location Anonymity in Indoor Spaces
PhD Dissertation
August 2016
Joon-Seok Kim
Advisor: Ki-Joune Li
Department of Computer Science and Engineering, PNU

A preliminary version of the study appeared in GeoInformatica.
abstract
Abstract
With the expansion of wireless-communication infrastructure and the evolution of indoor positioning technologies, the demand for location-based services (LBS) has been increasing in indoor as well as outdoor spaces. However, we should consider a significant challenge regarding the location privacy for realizing indoor LBS. To avoid violations of location privacy, much research has been performed, and location K-anonymity has been intensively studied to blur a user location with a cloaking region involving at least K-1 locations of other persons. Owing to the differences between indoor and outdoor spaces, it is, however, difficult to apply this approach directly in an indoor space. First, the definition of the distance metric in indoor space is different from that in Euclidean and road-network spaces. Second, a bounding region, which is a general form of an anonymizing spatial region (ASR) in Euclidean space, does not respect the locality property in indoor space, where movement is constrained by building components. Therefore, we introduce the concept of indoor location K-anonymity in this paper. Then, we investigate the requirements of ASR in indoor spaces and propose novel methods to determine the ASR, considering hierarchical structures of the indoor space. While indoor ASRs are determined at the anonymizer, we also propose processing methods for r-range queries and k-nearest-neighbor queries at a location-based service provider. We validate our methods with experimental analysis of query-processing performance and resilience against attacks in indoor spaces.
why
Background
- Growing demend of indoor location based-services (LBSs)
- Complex indoor sites such as convention centers, shopping malls and subway stations
- Infrastructure and mobile devices that enable indoor positioning
- Threat to privacy when using LBS through untrusted location-based service provider (LSP)
- Existing work is not efficient to apply to indoor spaces
What is limitation of previous work?
- Difference in distance matric
- Improper form of ASR
- Query processing for indoor location K-anonymity
Scope
- Query type:
- r-range query in indoor distance
- k-nearest neighbor query in indoor distance
- Target to protect:
- Location K-anonymity (re-identification)
- Cell l-diversity (semantic information)
- Spatial extent of ASR:
- Room level
- 3-dimensional space as well as 2-dimensional
- Responsibility: Trusted third party (centralized approach)
- Attack model:
- Center-of-ASR atack
- Replay attack
anonymity
System Model
We imploy a trusted third party (TTP) system between clients and LSPs to support location K-anonymization. The process consists of the following four steps.
- A client sneds an original spatial query, which specifies the client’s point location, to the anonymizer.
- The anonymizer alters the query and delivers the modified query with ASR, cloaking the client’s location, to the LSP
- The LSP performs the query and returns candidates that are a super set of the actual results.
- The anonymizer filters out candidates and sends back the actual results to the client.

Requirements for ASR Extension
- Resilience against attack
- Center-of-ASR attacks
- Replay attacks
- Homogeneity attacks
- Efficiency of query processing
- Preserving spatial locality
- Small ASR
- Avoiding fragmentation
ASR Determination
Hierarchical graphs (H-Graph) are a proper data structure to reflect indoor characteristics. Thus, we employ the hierarchical structure of an indoor space for indoor location K-anonymization. We suggest three methods to determine the ASR with consideration of the requirements.
- K-anonymity using H-Graph (KAH)
- K-anonymity using H-Graph by random selection (KAHR)
- K-anonymity on cell ordering using H-Graph (KAO)
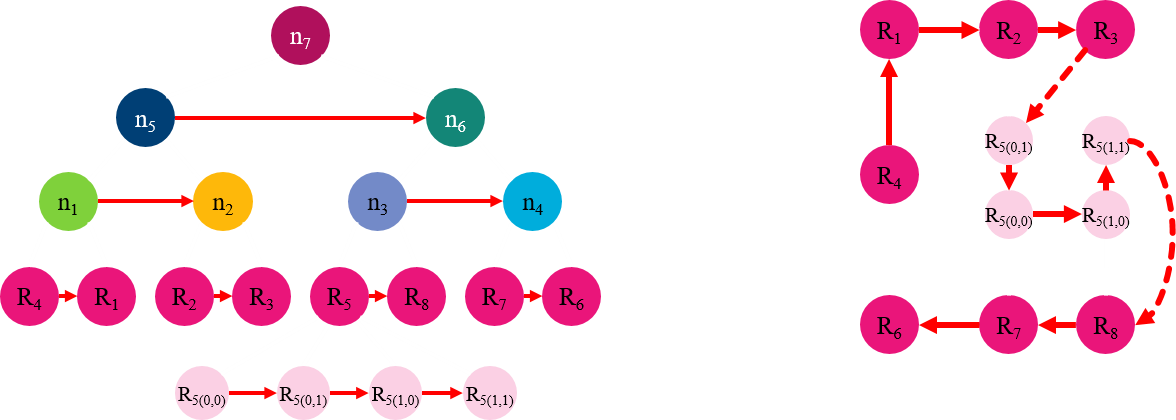
KAH
In order to satisfy K-anonymity, extend ASR from the leaf node where the requester is located.
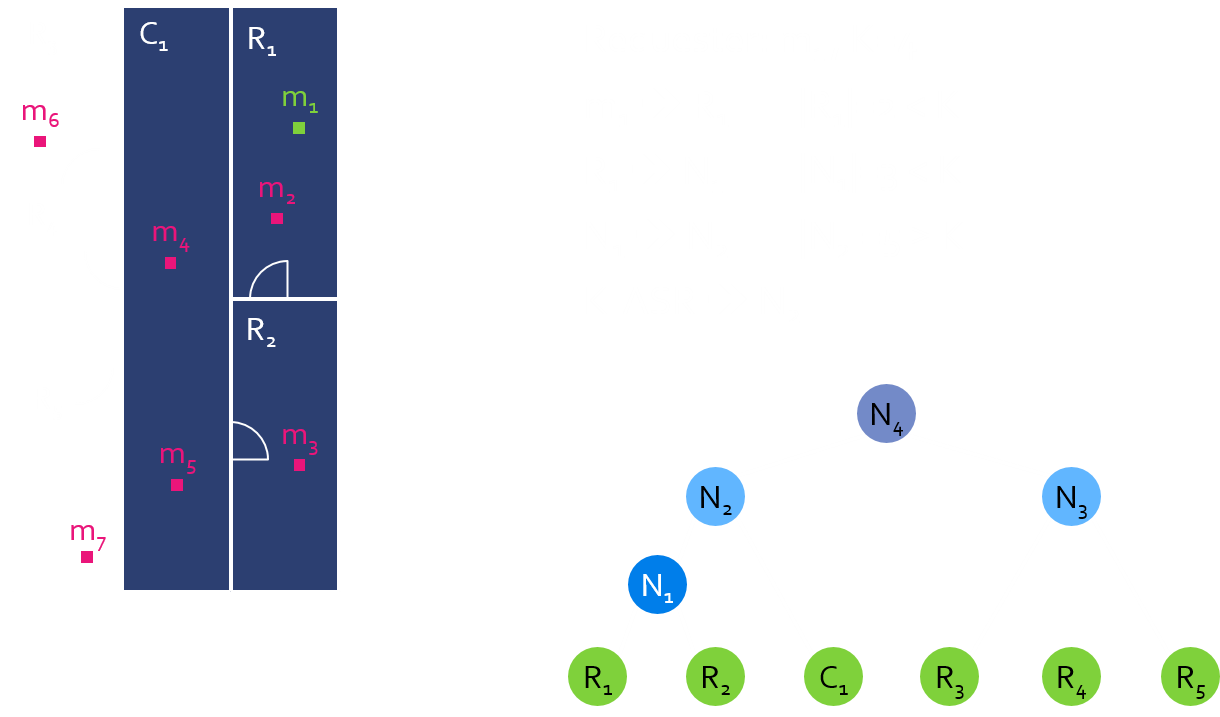
KAHR
In order to reduce exponential enlargement of ASR of KAH, randomly select cells in ASR of KAH.
KAO
In order to ensure reciprocity
- Make globally consistent groups that contain users
- Each group consists of at least K users.
Process of KAO
- Oragnize all buckets
- Find the bucket the requester belongs to
- Find all the cells containing users in the buckets
- Unite the cells as an ASR
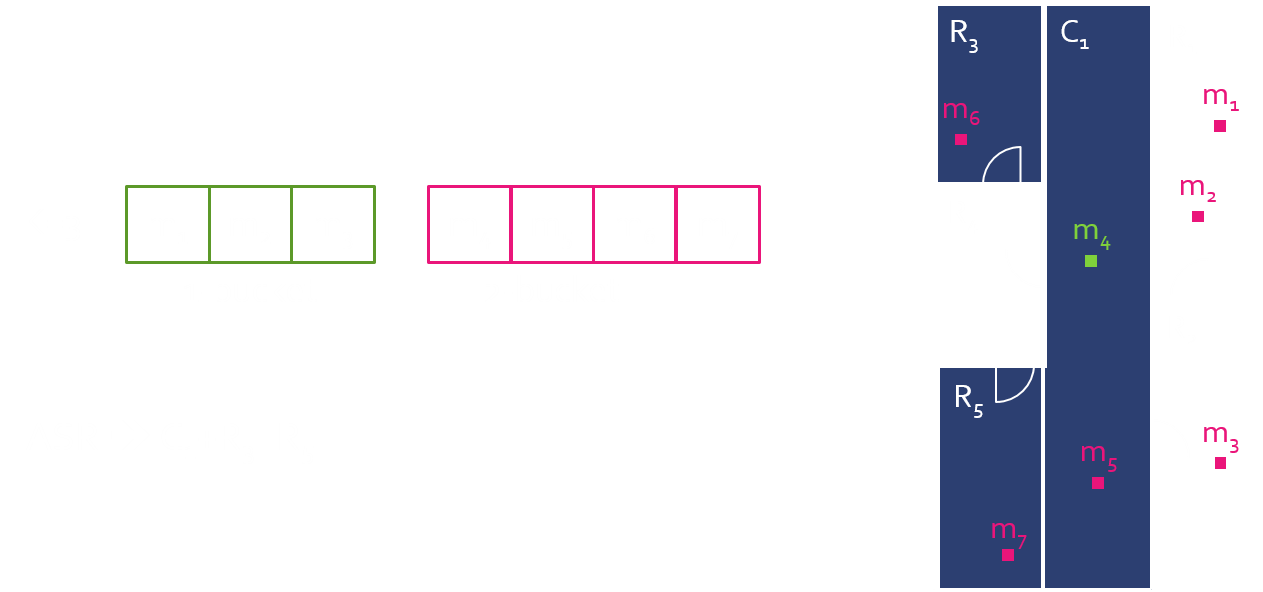
h-graph
Factors of K-Anonymization
- Security against inference attacks
- It is important to ensure that the identity of the requester should not be exposed with a probability larger than 1/K.
- Performance of query processing
- The area of ASR should be minimized for the performance of query processing
Strategy of Generating H-Graph: Minimize inefficiency
- Less average branching factor for performance
- Balanced for security
Measure of H-Graph: inefficiency = bf x height
Generating Base Graph
In order to generate the hierarchical graph, a base graph is required first.
Algorithm of Generating H-Graph
- Select victim nodes which should be merged in priority.
- Select target nodes that will be merged with the victim nodes.
linear mapping
Considerations for Linear Mapping in Indoor Space
- To partition indoor spaces into cells recursively
- To reflect indoor distance matric
- To assign a high priority to cluster objects in the same cell
- To minimize sume of indoor distance
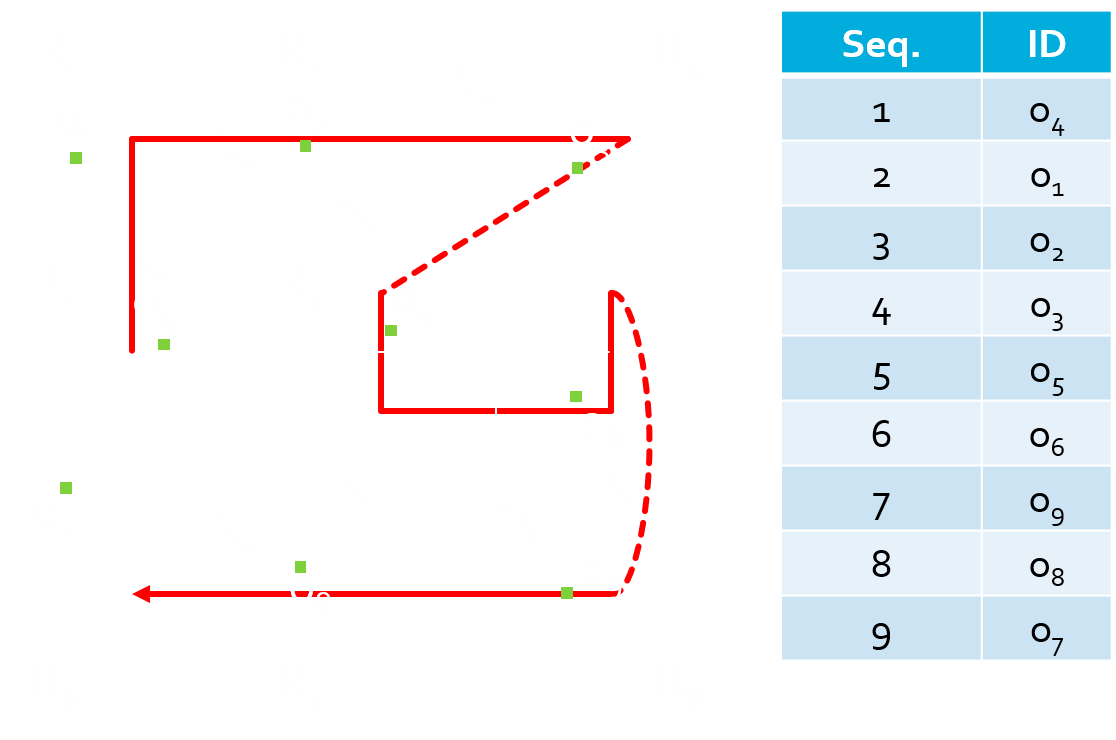
Linear mapping using H-Graph
Partitioning and generating H-Graph
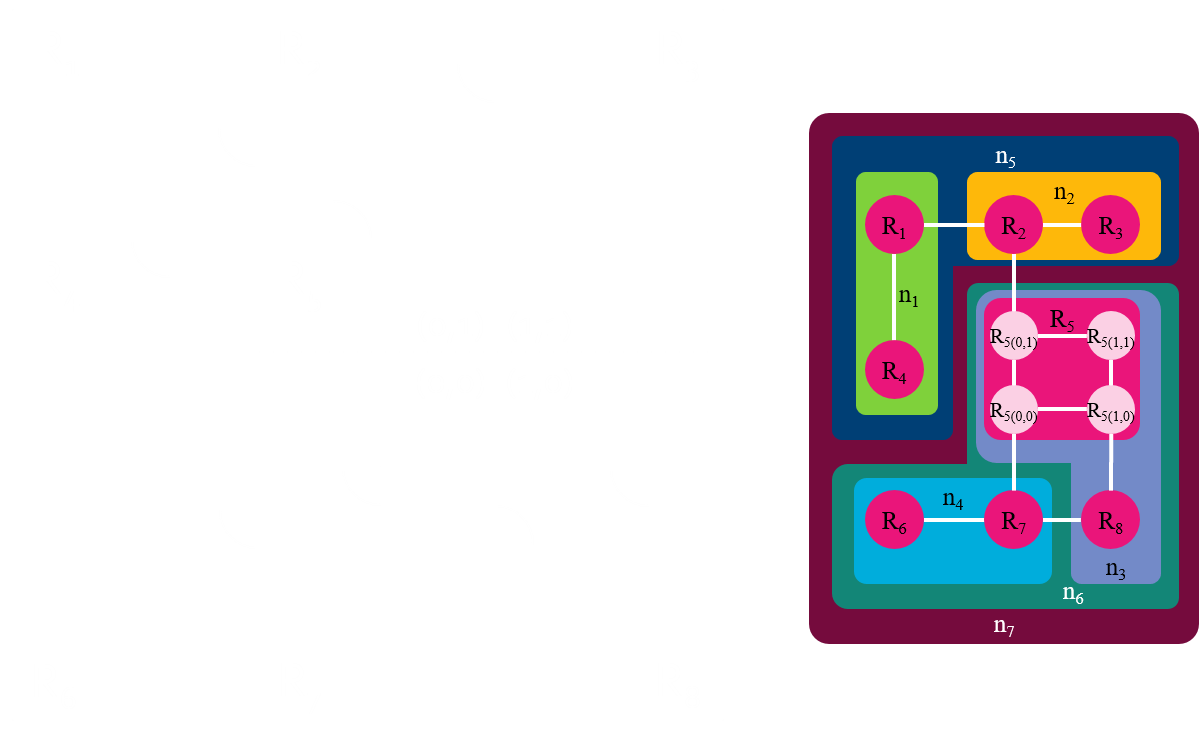
Linear mapping algorithm
- Traverse all nodes from the root node
- For each subgraph
- Find candidates of orderings with the minimum sum of indoor distance
- Choose the ordering connected to outer edges
experiments
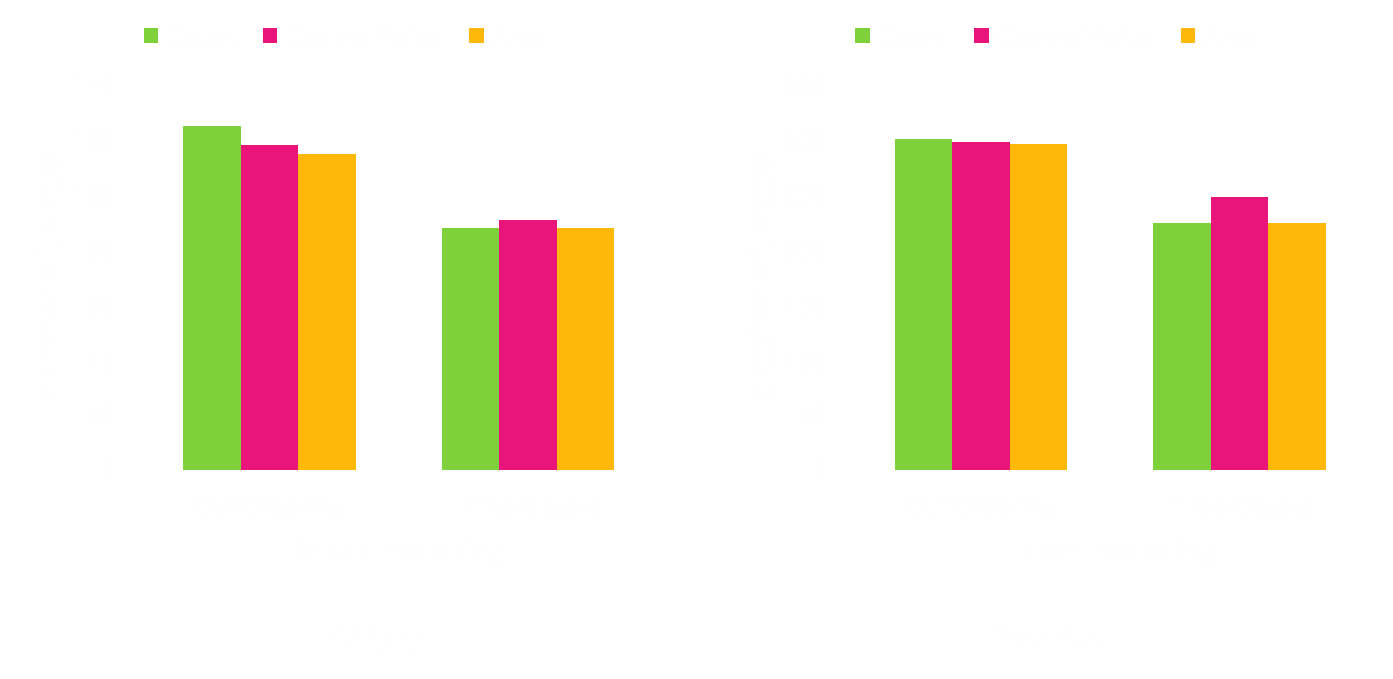
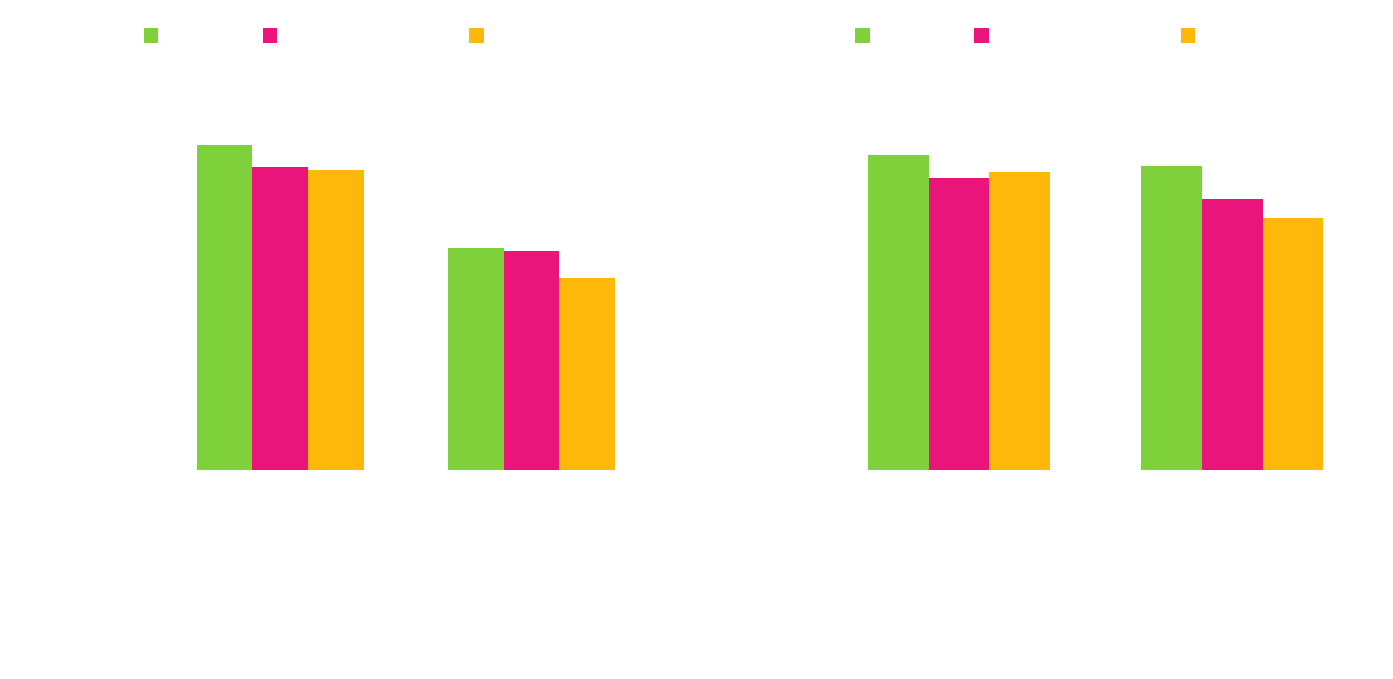
Summary of Experiments
- Characteristics of H-Graph
- Comparison of depth
- Comparison of average bf
- Comparison of shapes with visualization
- Analysis of resilience against attacks
- Comparison of success rate of center-of-ASR attack
- Comparison of inference probability of replay attack
- Comparison of success rate of replay attack
- Analysis of location K-anonymity at the anonymizer
- Comparison of areas of ASR
- Comparison of counts of cells
- Comparison of the number of doors of ASR
- Analysis of query processing with the ASR at the LSP
- Comparison of the number of candidates
- Comparison of response time
- Analysis of linear mapping
- Comparison of the number of jumps
- Comparison of distance of jumps
Experiment Setup
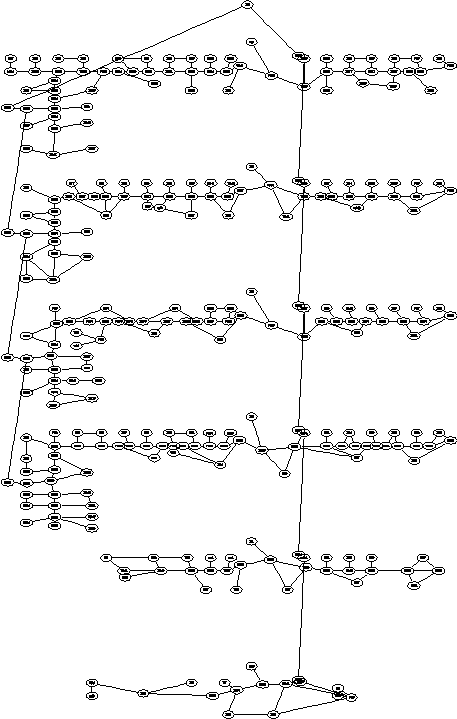
Feature of LAB313 buiding dataset
| Attributes | Values |
|---|---|
| # of subspaces | 302 |
| # of floors | 7 |
| avg. area of cells | 30.8m |
| var. area of cells | 95.8m |
| avg. degree | 2.4 |
Feature of Avenuel building dataset
| Attributes | Values |
|---|---|
| # of subspaces | 703 |
| # of floors | 6 |
| avg. area of cells | 70.6m |
| var. area of cells | 90.5m |
| avg. degree | 2.2 |
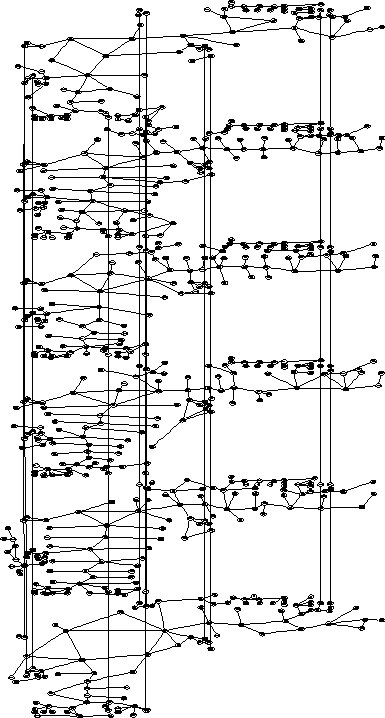
Summary of parameters for experiments
| Parameters | Values |
|---|---|
| Number of users | 200, 400, 600, 800, 1000 |
| Anonymity degree K | 5, 10, 15, 20, 25 |
| Diversity degree l | 1, 5, 10, 15, 20, 25 |
| Anonymity method | KAH, KAHR, KAM, KAO |
| H-Graph algorithm | ControlValue, Count, Area |
| Range query param r | 5, 10, 15, 20, 25 |
| NN query param k | 5, 10, 15, 20, 25 |
Characteristics of H-Graphs
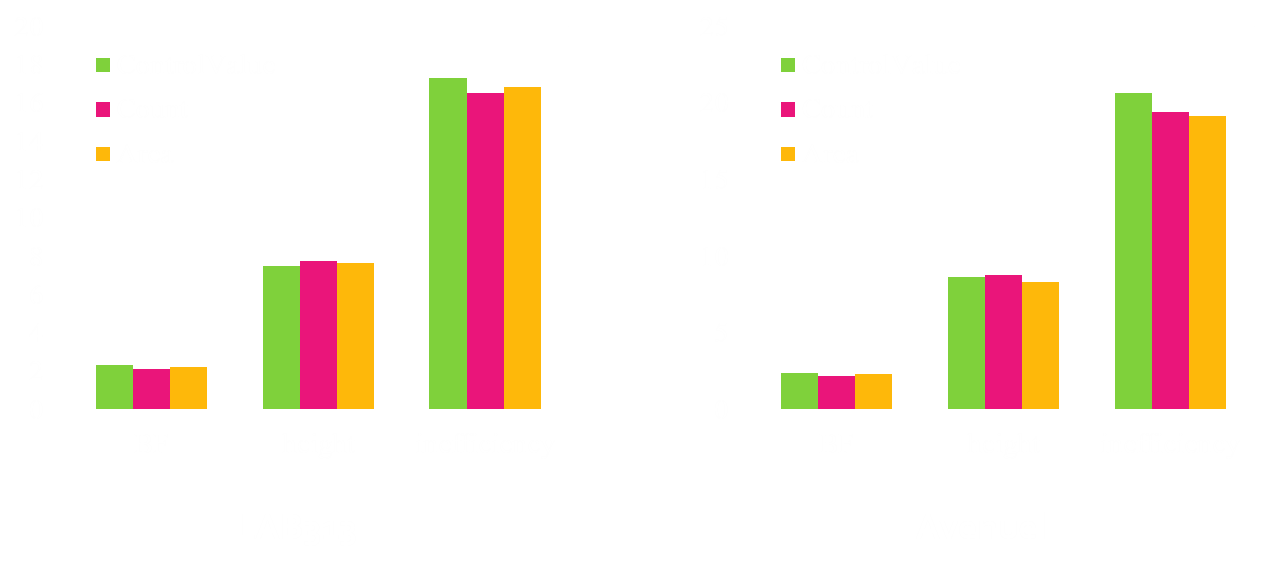
Analysis of Resilience against Attacks
Center-of-ASR attack
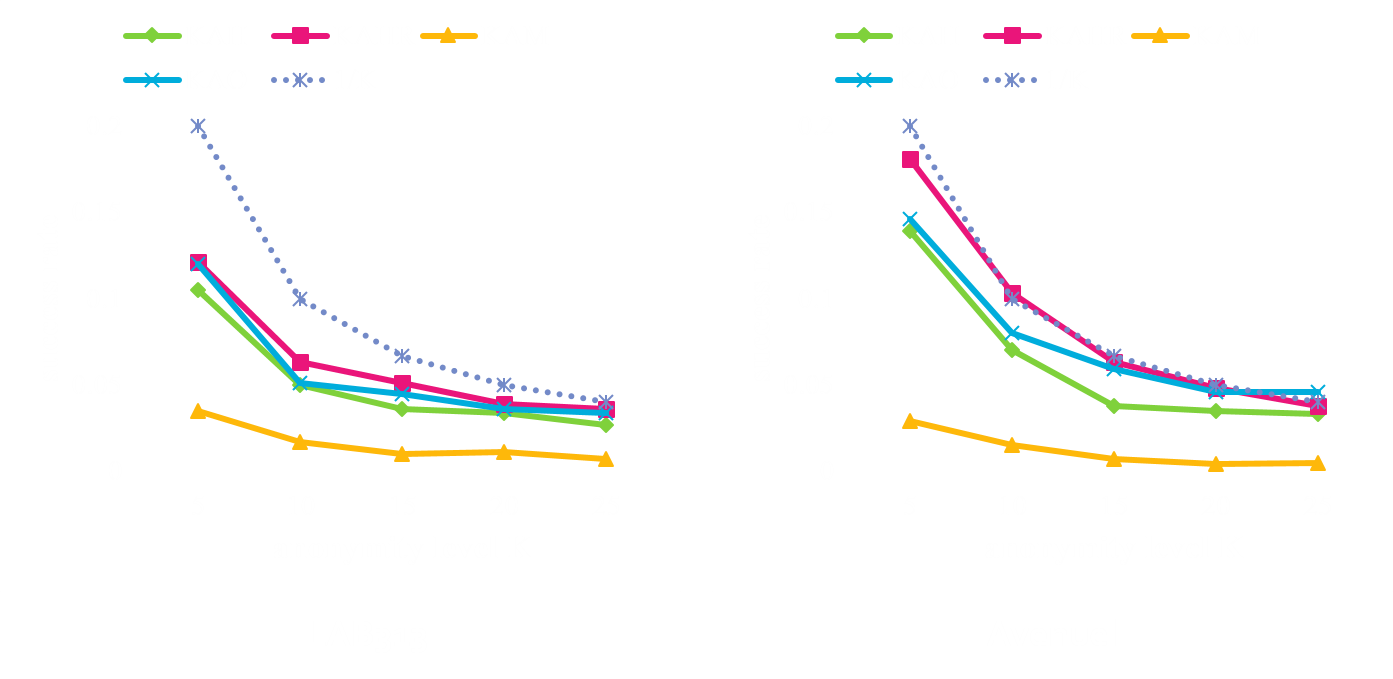
Replay attack
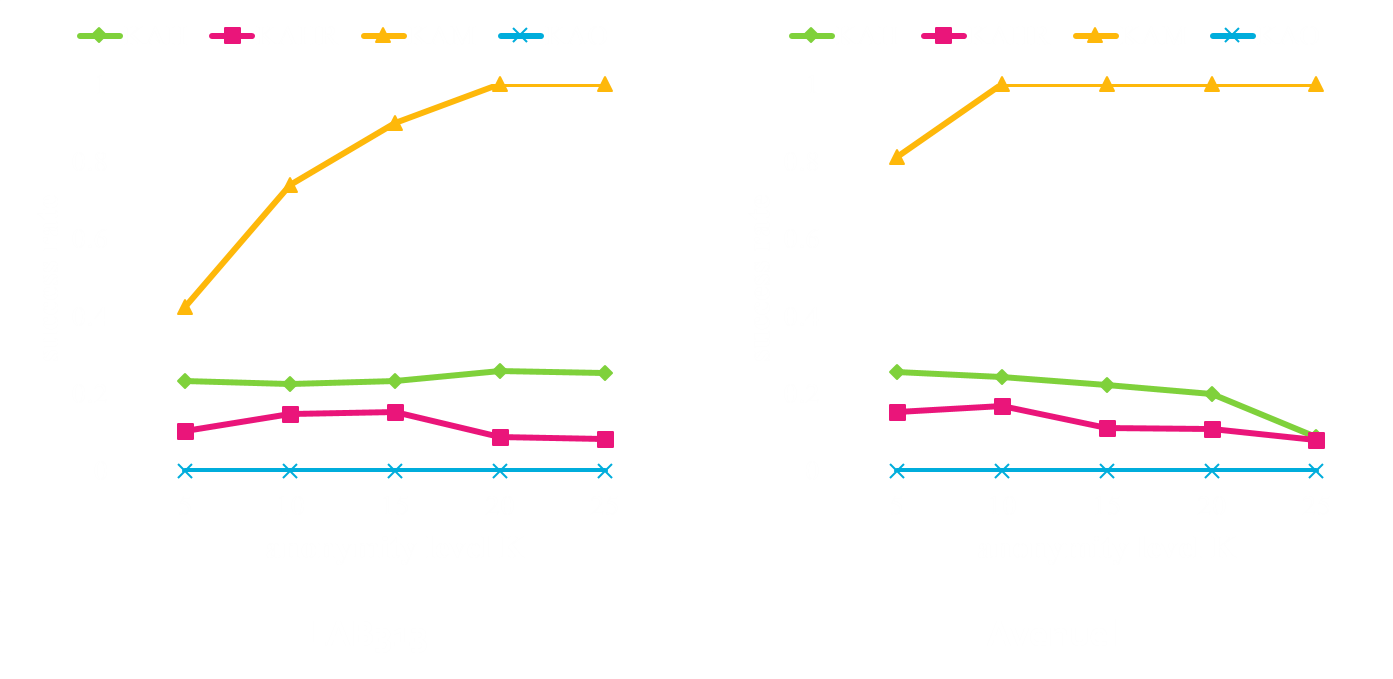
Analysis of K-Anonymization at the Anonymizer
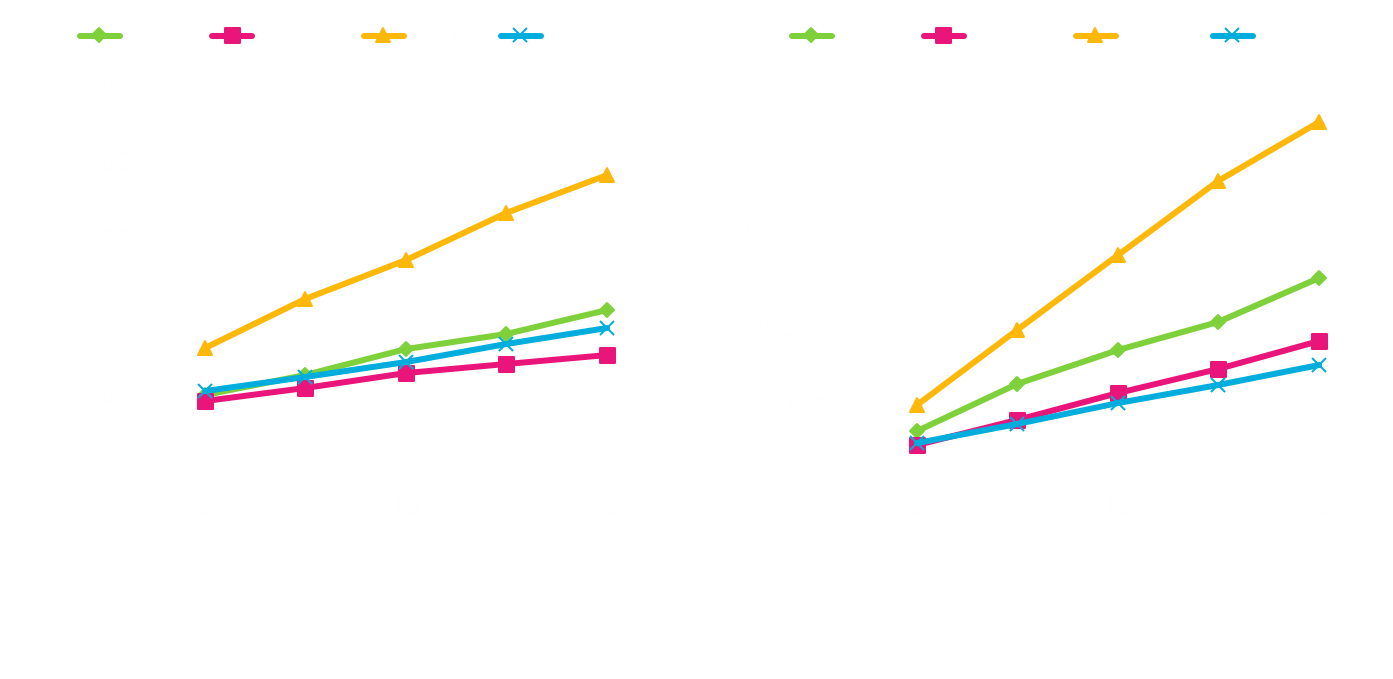
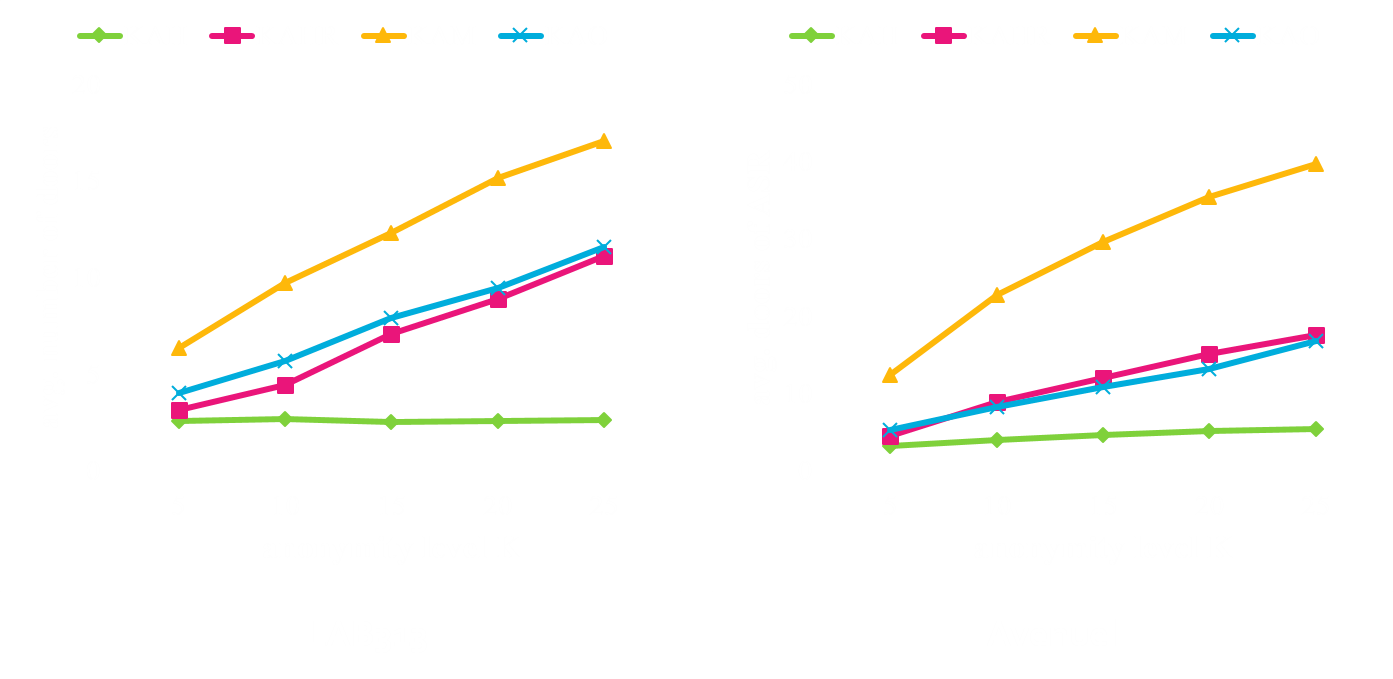
Analysis of Query Processing with the ASR at the LSP
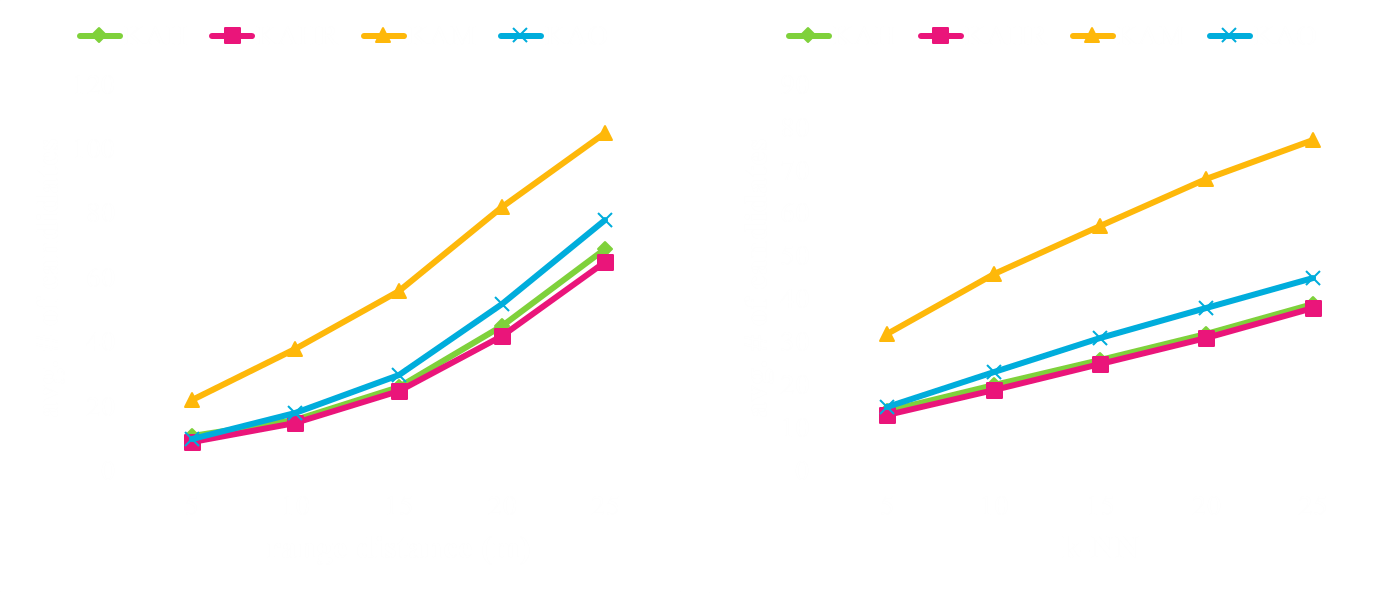
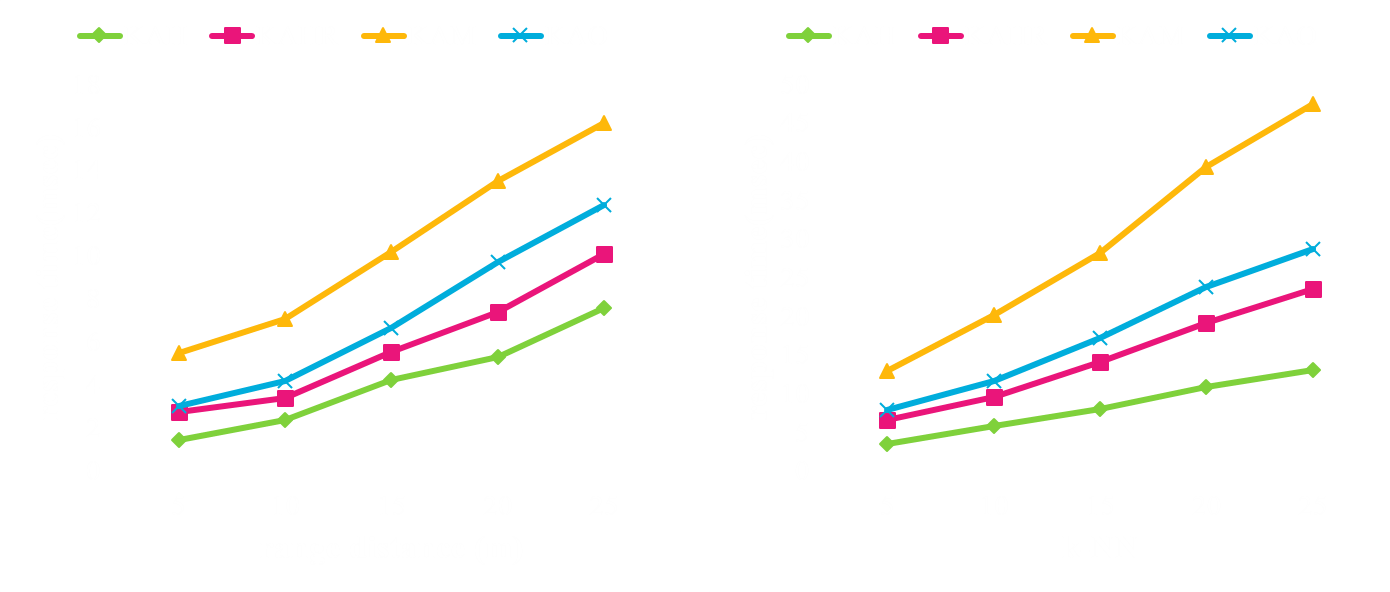
Analysis of Linear Mapping